

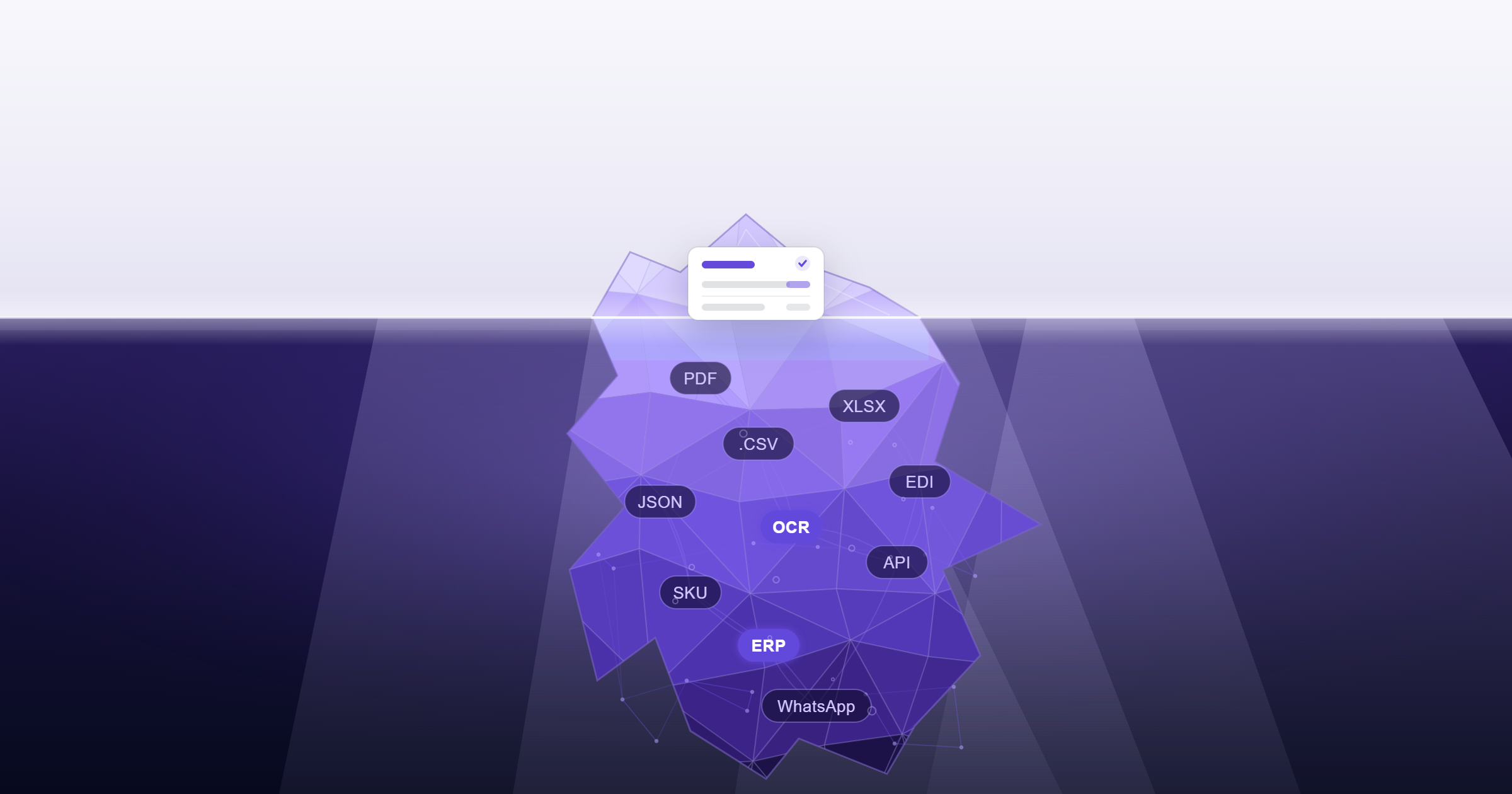
Un scanner de commandes clients ne vaut que ce qu'il sait. Et ce qu'il sait dépend directement de la qualité de la knowledge base sur laquelle il s'appuie. C'est cette dimension, souvent sous-estimée lors des comparaisons d'outils, qui fait pourtant toute la différence entre un système qui traite les cas simples et un système qui couvre l'ensemble des situations réelles.
La connaissance, condition préalable à l'automatisation
Automatiser le traitement d'une commande client, c'est résoudre une série de questions en quelques secondes : quel produit est demandé, dans quelle quantité, à quel prix convenu, avec quelles conditions de livraison ? Pour un opérateur humain expérimenté, ces questions trouvent leur réponse dans une combinaison de mémoire, de réflexes métier et d'accès aux bons documents. Pour un outil automatisé, cette même capacité repose entièrement sur sa knowledge base.
Sans elle, le scanner de commandes travaille à l'aveugle. Il peut reconnaître une référence exacte dans un catalogue, mais il ignore que ce client a une table de correspondance spécifique, que ce contrat prévoit des prix dégressifs, ou que ce produit est commercialisé sous trois libellés différents selon les marchés. Ces informations existent quelque part dans l'entreprise : le problème est de les rendre accessibles au moment où elles sont nécessaires.
Knowledge base et scanner de commandes : ce qu'elle doit vraiment contenir
Une knowledge base efficace n'est pas un simple répertoire de références produits. Elle doit agréger plusieurs couches de connaissance complémentaires :
- Les contrats clients : conditions tarifaires négociées, remises applicables, unités de vente convenues, délais et modalités de livraison spécifiques. Un ordre de commande ne peut pas être traité correctement si l'outil ignore ce qui a été contractuellement défini.
- Les tables de correspondance de références : chaque client qui commande avec ses propres codes internes a besoin d'une table de conversion fiable, enrichie au fil du temps à partir des commandes précédentes et des validations des opérateurs.
- Les fiches produits détaillées : libellés alternatifs, synonymes, désignations techniques, codes EAN, unités de conditionnement, équivalences entre références. Un produit peut être demandé de dizaines de façons différentes selon le client, le secteur ou le pays.
- Les historiques de commandes : savoir ce qu'un client a commandé par le passé, dans quelles quantités et avec quels codes, permet de lever une grande partie des ambiguïtés sur les nouvelles commandes.
Le problème du démarrage à froid
L'un des défis classiques des outils de traitement automatisé est le démarrage à froid : au moment du déploiement, l'outil ne connaît rien. Il doit apprendre en traitant des commandes, ce qui signifie que les premières semaines sont dégradées, avec un taux d'erreur élevé et une intervention humaine importante.
Ce problème disparaît lorsque la knowledge base peut être alimentée dès le départ avec les données existantes : contrats dans le CRM ou l'ERP, tables de correspondance dans des fichiers Excel ou des bases de données internes, fiches produits dans le PIM. Une knowledge base bien conçue peut ingérer ces sources dès le premier jour, sans attendre que l'apprentissage en production comble les lacunes.
Une base de connaissance qui s'enrichit en continu
Chaque commande traitée, chaque validation d'opérateur, chaque correction apportée est une opportunité d'enrichir la connaissance disponible. Une référence interne client résolue manuellement une première fois ne devrait jamais nécessiter d'intervention manuelle la fois suivante. Un libellé ambigu correctement interprété une fois devient une règle consolidée pour les occurrences futures.
Cette capitalisation continue transforme la base de connaissance en un actif stratégique qui prend de la valeur avec le temps. Plus l'outil traite de commandes, plus il devient précis, plus le taux d'automatisation augmente et moins les équipes passent de temps sur des tâches à faible valeur ajoutée.
La knowledge base de Volta : une approche avancée
Volta intègre une base de connaissance structurée pour accueillir dès le déploiement les données existantes de l'entreprise : contrats, référentiels produits, tables de correspondance, historiques de commandes. L'outil n'arrive pas vierge : il arrive instruit.
Cette base est entièrement optionnelle. Chaque fournisseur reste libre de décider s'il souhaite l'alimenter dès le départ ou laisser Volta construire sa connaissance progressivement. Les deux approches fonctionnent, la différence est une question de vitesse : une knowledge base alimentée dès le lancement comprime en quelques jours ce qui prendrait autrement plusieurs mois d'apprentissage en production.
L'architecture permet également d'intégrer des sources externes au fil des besoins, sans interruption de service et sans re-paramétrage global. Le résultat est un taux de couverture qui progresse régulièrement vers l'exhaustivité : non pas un outil qui traite bien les cas courants, mais un outil qui couvre l'ensemble des situations, y compris les plus complexes et les plus spécifiques à chaque client.
Du scanner de commandes transactionnel à l'intelligence opérationnelle
Un scanner de commandes sans base de connaissance solide est un outil transactionnel : il traite ce qui est simple et renvoie le reste à l'humain. Un scanner adossé à une knowledge base riche et vivante devient un véritable système d'intelligence opérationnelle : il comprend le contexte, mobilise la connaissance pertinente, propose des interprétations argumentées et apprend de chaque interaction.
C'est cette différence de nature, plus que toute comparaison de fonctionnalités, qui détermine la valeur réelle d'un outil de traitement automatisé des commandes sur le long terme.
Prêt à donner à votre scanner de commandes une longueur d'avance dès le premier jour ?
Découvrez comment Volta intègre votre knowledge base existante pour automatiser vos commandes avec précision dès le lancement.






