
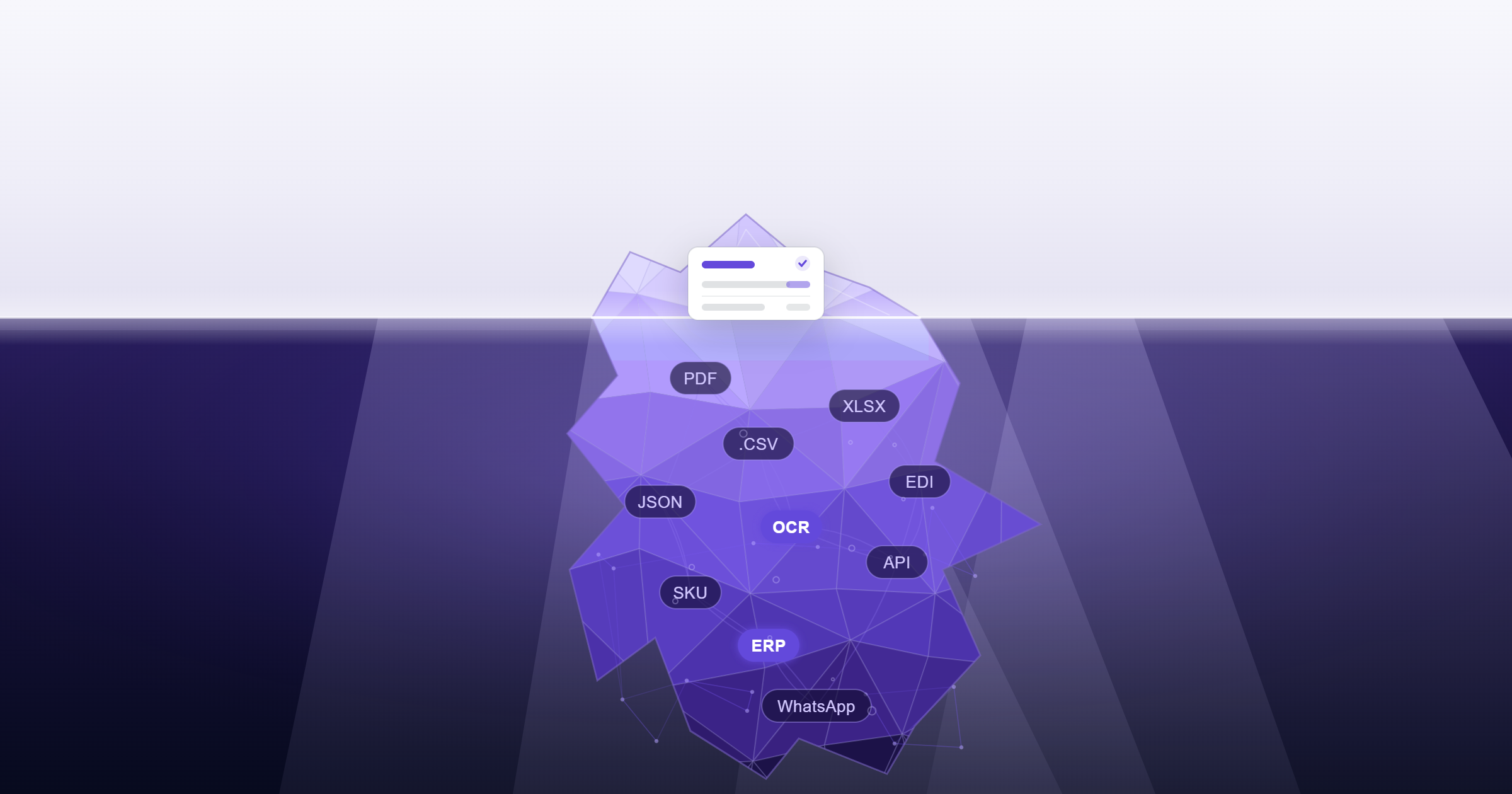
Tout le monde pense qu'un scanner de commandes est simple à construire. Jusqu'au moment où l'on essaie. Un document arrive, les produits sont identifiés, une commande est créée : sur le papier, cela ressemble à un copier-coller avec un peu d'OCR par-dessus. La réalité est fondamentalement différente. Construire un prototype qui semble fonctionner est facile ; construire un scanner de commandes prêt pour la production l'est beaucoup moins. Voici pourquoi.
Et le plus cruel dans tout cela ? Construire quelque chose qui semble fonctionner est vraiment facile. C'est précisément pour cette raison que tant d'équipes, de chefs de produit et d'éditeurs ERP sous-estiment la vraie portée du problème.
Le piège du prototype : les 20% faciles
Soyons honnêtes. Un prototype fonctionnel de scanner de commandes n'est pas difficile à construire. Donnez trois à six mois à une équipe de développement correcte, et elle aura quelque chose qui parse des PDF natifs, extrait des références et des quantités, fait correspondre avec un catalogue et pousse des données structurées dans un ERP. Ce sera impressionnant en démo. Les parties prenantes seront convaincues. Le projet sera déclaré réussi.
Le problème, c'est que ce qui a été construit à ce stade couvre les 20% faciles : les commandes déjà propres, complètes et bien formatées. Ce sont les commandes où :
- Le document est un PDF natif ou un fichier Excel propre
- Les références du fournisseur sont explicitement indiquées
- Les quantités et les unités sont sans ambiguïté
- Le nom du client correspond exactement à la base de données
- La mise en page est cohérente, page après page
C'est une catégorie de commandes parfaitement réelle. Pour cette part du volume entrant, un scanner basique fonctionne à merveille : références exactes, unités standard, une page, traitement en quelques secondes. C'est pourquoi le prototype paraît si convaincant. L'équipe l'a construit sur des données propres, testé sur des données propres et démontré sur des données propres. Évidemment que cela marche.
Mais en production, les données propres sont l'exception, pas la règle.
Le monde réel : désordonné, incohérent, imprévisible
Les vrais documents clients sont une tout autre affaire. Les références dans les commandes entrantes sont des références clients, pas des références fournisseurs. Un client appelle un produit « REF-0042-BIS » en interne ; le catalogue le connaît sous « PRD-9871-A ». Aucune correspondance exacte n'est possible sans table de mapping, et cette table n'existe pas encore, parce que chaque client a construit sa propre nomenclature au fil des années.
Les unités ne correspondent pas davantage. Un client commande en kilos ; l'ERP n'accepte que des unités. Le facteur de conversion n'est pas universel : il dépend du produit, du format d'emballage, du contrat négocié, et parfois d'une règle métier qui n'existe que dans la tête d'un commercial présent depuis quinze ans.
Les langues varient. Les formats changent sans préavis. Les descriptions sont partielles, abrégées ou tout simplement incorrectes. « Belt 457J » signifie quelque chose de très précis pour quelqu'un qui connaît la gamme. Pour un extracteur de texte généraliste, c'est du bruit. Et chaque client a ses propres conventions, construites sur des années, qu'aucun moteur de règles statique ne peut anticiper.
La couche avancée : là où vivent réellement 50 à 60% des commandes
Dès qu'une équipe essaie de dépasser les 20% faciles, elle rencontre une classe de problèmes qualitativement différente. Il ne s'agit plus d'ajouter des règles de parsing, mais de construire de l'intelligence. C'est exactement le terrain de l'automatisation des commandes B2B par l'IA.
- Gestion des références clients : maintenir des tables de correspondance de codes par client, tenues à jour au fur et à mesure que les produits évoluent.
- Synonymes et abréviations : comprendre que « U », « UN », « Unité », « Pièce », « P », « UNT » et « Boîte » peuvent vouloir dire la même chose, ou pas, selon le contexte.
- Apprentissage continu : lorsqu'un opérateur corrige une correspondance, cette correction doit être mémorisée et appliquée automatiquement la fois suivante.
La conversion d'unités paraît trompeusement simple. « Convertir des kilos en unités » : en réalité, les flux de commandes B2B sont remplis de complexités commerciales. Un client peut commander en kilos, boîtes, packs, couches, palettes, sous-unités, ou en unités commerciales qui n'existent même pas dans l'ERP. Les règles de conversion de conditionnements diffèrent selon le client, le produit, le canal de vente, le format d'emballage et le contrat négocié. Certaines conversions ne sont pas mathématiquement déterministes et nécessitent un contexte métier pour être interprétées correctement.
Ce n'est plus de l'OCR. C'est de l'intelligence opérationnelle métier. Concrètement, 50 à 60% des commandes entrantes nécessitent ce niveau de sophistication. Et même les scanners de commandes les plus avancés du marché aujourd'hui traitent au mieux 70 à 80% du volume entrant. Quiconque prétend le contraire n'a pas encore traité assez de volume, ou n'est pas honnête dans ses chiffres.
La couche expert : les 15 à 20% les plus difficiles
Au sommet de la pyramide de complexité se trouve une catégorie de commandes qui exige des capacités allant bien au-delà du parsing de documents. Ce sont les commandes les plus longues à traiter manuellement, les plus précieuses, et celles qui créent le plus de friction quand elles sont mal traitées.
- Commandes ouvertes : livraisons étalées sur plusieurs mois, avec des quantités variables par ligne et par date.
- Documents multi-commandes : plusieurs commandes distinctes regroupées dans un seul fichier.
- Documents hybrides : tableaux structurés mêlés à du texte libre, des annotations manuscrites et des spécifications jointes.
Faire correspondre des produits sans aucune référence ni libellé, uniquement à partir d'une description comme « 6 courroies roulement sphérique à contact lisse Elges GE40 », nécessite de la compréhension sémantique, de la recherche vectorielle et de la connaissance du domaine, pas de la correspondance de chaînes de caractères. Le traitement en flux tendu, où une commande est ingérée, mise en correspondance, validée et poussée dans l'ERP sans aucune intervention humaine, n'est réalisable que lorsque le système a accumulé assez de connaissance contextuelle sur ce client, ses habitudes, son catalogue et ses cas particuliers pour agir avec confiance.
Ces 15 à 20% ne sont pas un cas limite de niche. Ils incluent certaines des transactions à plus haute valeur de l'entreprise. Ne pas les traiter ne les fait pas disparaître : cela déplace simplement le coût vers les opérateurs humains, introduit des délais et crée une friction systématique avec les clients les plus exigeants.
La distance entre une démo et un scanner de commandes en production
L'écart entre un prototype convaincant et un scanner de commandes vraiment prêt pour la production ne se mesure pas en semaines. Il se mesure en couches d'intelligence.
- Fonctionnalités de base (~20% des commandes) : documents propres, références exactes, formats standard.
- Fonctionnalités avancées (~50 à 60% des commandes) : références clients, conversion d'unités, apprentissage, correspondance approximative.
- Fonctionnalités expert (~15 à 20% des commandes) : correspondance sémantique, commandes ouvertes, traitement en flux tendu.
Chaque couche nécessite une ingénierie fondamentalement différente. Et chaque couche est plus difficile que la précédente, non pas de façon incrémentale, mais de façon catégorielle. Le piège du prototype est réel : les éditeurs ERP ajoutent le scanning de commandes à leur roadmap, les intégrateurs le présentent comme un quick win, et cela paraît convaincant en démo, parce que la démo utilise toujours des données propres. Les 80% restants se trouvent juste sous la surface, invisibles jusqu'à la mise en production, et soudainement présents partout.
Ce que cela signifie en pratique
Construire pour l'ensemble des commandes réelles n'est pas un luxe : c'est la différence entre un scanner de commandes et un vrai système industrialisé, capable de libérer vos équipes de la saisie manuelle.
Un test utile à poser à tout fournisseur : « Est-ce qu'un stagiaire sans formation pourrait ressaisir 100% des commandes clients ? » Si oui, un scanner basique suffit probablement. Mais dans la réalité, 99% des fournisseurs répondront non, parce qu'ils savent que c'est tout simplement impossible : chaque commande nécessite de l'attention, de la connaissance et de la prise de décision.
Cette connaissance et cette capacité de décision, c'est exactement ce qu'un scanner de commandes industrialisé doit encoder. Non pas dans un référentiel de règles, parce que les règles ne peuvent pas anticiper ce que les clients feront la semaine prochaine, mais dans un système capable d'apprendre, de raisonner et de s'améliorer en continu. C'est le vrai défi d'ingénierie, et l'un des problèmes d'automatisation les plus complexes de la distribution B2B.
Cet article est basé sur des recherches internes et une expérience en production sur de multiples secteurs et types de fournisseurs.
Toujours des questions ?
Découvrez les avantages de Volta pour votre entreprise. Réservez une démo gratuite dès maintenant.






